In this article, we'll talk about groups and ranges in regular expressions and how they can be used by translators in CAT Tools such as SDL Trados Studio.

Let's have a look at these regex components and some of their applications.

The previous post about quantifiers ends with a brief introduction of the function of the dot in regular expressions: a wildcard that represents any character.
Regex example: .*?,
Using a single dot will match any one character. Combining the dot with a quantifier will match more than one. This regex will match all the text up to a comma, as shown below:

A word of caution about the dot in regex
While it may seem tempting to use the dot wildcard frequently, one must be aware of potential undesired results.
For example, imagine that we want to find all the text that comes between straight quotation marks so we can later replace the straight quotation marks with curly quotation marks. Using a regex such as ".+" (a straight quotation mark followed by anything, one or more times, followed by a straight quotation mark) would seem like an easy solution, but look at what can happen below:

Instead of getting two matches: "I will see you there" and "don't be late", we get a single match, from the very first quotation mark in the segment to the very last one.
These undesired results are not always evident when using a regular expression in the SDL Trados Studio display filter, for example, so it's always a good idea to test the regex in a regex tester such as regexstorm.net/tester, which I will use for the examples in this article.
Bonus tip: A better regex to find each separate instance of text inside straight quotes is "[^"]*".


Regex example: col(o|ou)r
In regular expressions, the vertical bar or pipe character | indicates alternation. Using the pipe tells the regex to match everything to the left or everything to the right of the pipe, as shown here:

Here, the strings that match the regex colo|our are "colo" and "our". If we want to match "color" and "colour" instead, we need to use parentheses:

Look at the example below to see how alternation can be used to match any of the days of the week.

Now, you may notice that in this example, all the text to the left or right of the pipe is matched, whether it's a whole word or not. If what we want to do is match whole words only, we can use parentheses to create a group and then apply word boundaries to the entire group.

I use this regex in a verification rule in SDL Trados Studio to alert me about segments where the day of the week is not present in the source but is present in the target:


Regex example: (\d+,)+
Parentheses are used to create groups in regular expressions. Look at this example:

Here, the regex \d+, is matched twice, once by "123," and once by "456,". If instead we want to include both instances in a single match, we need to add parentheses to the expression and then add the + quantifier to the group.

A group can also be a single character, as in the example below, where the ? quantifier (which means 0 or 1) is used to make the s character optional.

Lastly, groups have two purposes in regular expressions: to organize information and to capture the contents of the group. The captured information is "remembered" by the regex engine and can later be used for backreferences or substitutions.
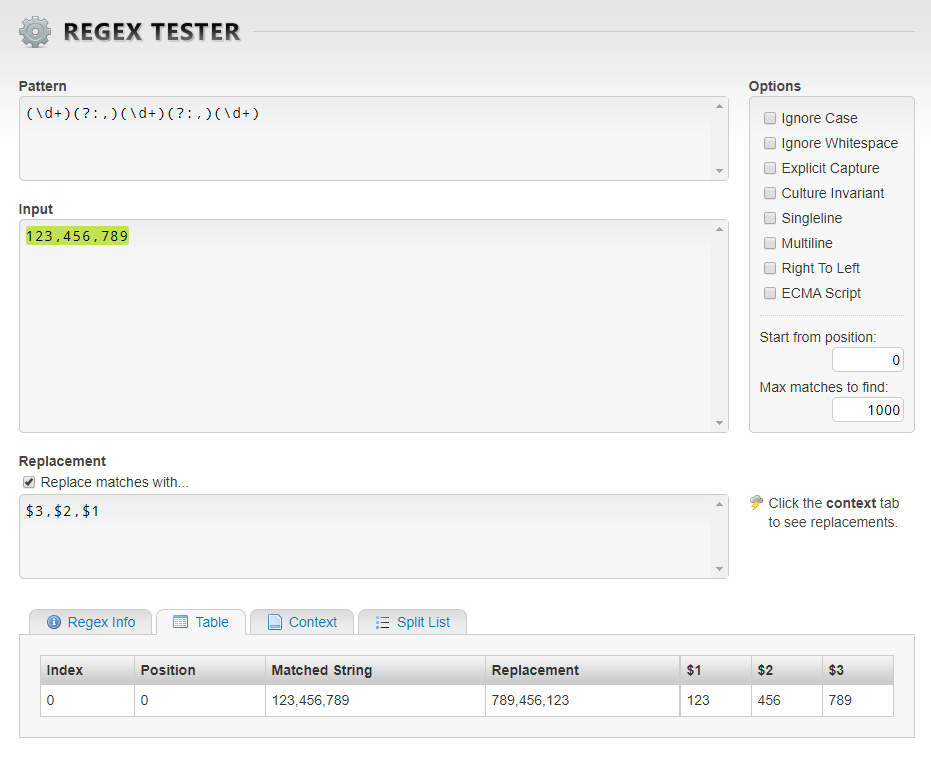
Consider this example:

Here, the regex pattern has been organized into five groups, as shown in the table above, at the bottom of the regex tester window. Each group is assigned a consecutive number, so group 1 captures the character sequence 123, group 2 captures the first comma, group 3 captures the character sequence 456, group 4 captures the second comma and group 5 captures the character sequence 789.
In the replacement pattern, we can rearrange the groups by representing each group with the dollar sign followed by the group number. In our example, the groups have been rearranged to $5$2$3$4$1, resulting in the replacement string 789,456,123.
Note: The same result can be achieved by using commas instead of the numbered groups $2 and $4, which would make the replacement pattern $5,$3,$1.

In addition to regular groups, there is a less commonly used type of group, called passive or non-capturing. The only difference between a non-capturing group and a regular group is that a non-capturing group organizes the information contained in the group, but doesn't capture it, that is, the information in the group is not assigned a group number.
Let's use the same example we used before to understand how this works. Instead of having five regular groups, the commas will now be placed inside non-capturing groups by using the following syntax: (?:,).
While we still have 5 groups organizing the information, two of them are non-capturing, so the number of groups available for substitutions (replacement operations) is reduced to three, as shown in the table at the bottom of the regex tester window.
With this, the replacement pattern to achieve the same result as in the previous example is now $3,$2,$1.
While there aren't many use cases that come to mind for using non-capturing groups, they can come in handy when one wants to keep the number of capturing groups down to avoid having to keep track of too many group numbers.

Regex example: \d+[abz?*]
Placing characters inside square brackets means that any one of the characters in that set can be matched in that position, in no particular order. Have a look at this example:

Note that when used inside a character set range, metacharacters don't need escaping.

Regex example: \d+[^abz?*]
Adding a caret (^) inside the square brackets means that the characters included inside the square brackets should be excluded.

This is how the quotation mark regex mentioned earlier works: "[^"]*" will be matched by a quotation mark followed by zero or more of any character except a quotation mark, followed by a quotation mark.

Regex example: [A-Z][a-z]+
Lowercase and uppercase letters can be helpful when we need to specify case, for instance, when we want to find words that begin with a capital letter.

The sample regex here means one uppercase letter followed by one or more lowercase letters. But if this is the case, then how come the words "Añoranzas" and "Épicas" are not matched? The reason is that the ranges [A-Z] and [a-z] include only characters in the English alphabet. A solution to include other non-English letters is to add them to the character set:

While these examples use the full range of letters in the English alphabet, it's also possible to limit the range. In the example below, by limiting the uppercase range to "A-I", the words "The" and "La" are excluded from the matches.

While we could say that [0-9] is basically the same as \d, the [0-9] character range offers a bit more flexibility, as we can easily throw in a few other characters into the range to help us cover a variety of number formats.

In this example, the regex matches numbers with decimals, commas, fractions, and dashes, without having to come up with any complex expressions. While this may not be the most elegant solution for someone writing code for a program, it certainly can be a time-saver for a translator wanting to filter segments.
With this, we have come to the end of this article. If you'd like to have a copy of my cheat sheet, you can download it here:

Happy regexing!

Was reminded of this post after a question popped up in the SDL Community (I have suggested that the person asking visits this blog post).
ReplyDeleteThank you!
Delete